
Classes de SFS para as CONSOANTES do português são:
| um sou vozeado e seu correspondente desvozeado | [p]-[b]; [t]-[d]; [k]-[ɡ]; [tʃ]-[dʒ]; [f]-[v]; [s]-[z]; [x]-[ɣ]; [h]-[ɦ] |
| uma oclusiva e as fricativas e africadas com ponto de articulação idêntico ou muito próximo | [t]-[s]; [d]-[z]; [t]-[tʃ]; [d]-[dʒ]; [ʃ]-[tʃ]; [ʒ]-[dʒ] |
| as fricativas com ponto de articulação muito próximo | [s]-[ʃ]; [z]-[ʒ]; [x]-[h]; [ɣ]-[ɦ] |
| as nasais entre si | [m]-[n]; [m]-[ɲ]; [n]-[ɲ] |
| as laterais entre si | [l]-[ʎ]; [l]-[lʲ]- [ʎ]-[lʲ]; [l]-[ɫ] |
| as vibrantes entre si | [ɾ]-[ř] |
| as líquidas (laterais, vibrantes e tepe) entre si | [l]-[ɾ]; [l]-[ř] |
| sons com propriedades articulatórias muito próximas | [n]-[nʲ]; [nʲ]-[ɲ]; [ɲ]-[ỹ]; [ʎ]-[y]; [lʲ]-[y] |
Classes de SFS para as VOGAIS do português são:
Os SFS nas vogais tipicamente diferenciam uma ÚNICA propriedade articulatória.
O O contraste fonêmico define fonemas. O modelo fonêmico propõe dois tipos de contraste:
Sempre que dois SFS estão em contraste dois fonemas são definidos através do teste do par mínimo.
Pares mínimos são definidos a partir de um par de palavras que permite identificar fonemas. O teste do par mínimo consiste em atestar duas palavras com significados diferentes cujas pronúncias se diferenciam apenas em relação a um dos sons em cada palavra. Cada um dos sons envolvidos será um fonema.
As palavras [ˈfakə] ‘faca’ e [ˈvakə] ‘vaca’ constituem um par mínimo porque têm significados diferentes e a única diferença sonora entre elas é o som inicial. Define-se assim que /f/ e /v/ são fonemas do português que são pronunciados como [f] e [v] respectivamente.
O par mínimo [ˈfakə] ‘faca’ e [ˈvakə] ‘vaca’ define que /f/ e /v/ são fonemas do português. Neste caso, atestou-se o contraste em ambiente idêntico (CAI). Contudo, em análises preliminares pode ser necessário fazer uso do contraste em ambiente análogo (CAA). No contraste em ambiente análogo os contextos são quase idênticos, mas diferem em mais de um som nas palavras. O par de sons identificado como “potenciais fonemas” deverá buscar comprovação através do contraste em ambiente idêntico na identificação dos fonemas da língua.
Em alguns poucos casos fonemas são identificados mesmo sem pares mínimos serem encontrados. Nestes casos os sons não ocorrem no mesmo contexto e sendo assim seria impossível encontrar pares mínimos. Por exemplo, no inglês o som [ŋ] só ocorre em final de sílabas como, por exemplo, em ‘ring’ [rɪŋ] – e o som [h] só ocorre em início de sílaba como, por exemplo em ‘house’ [haʊs]. Portanto, é impossível encontrar uma palavra em que [ŋ] ocorra no início da sílaba para contrastá-lo com uma sílaba que se inicia com [h]. De maneira análoga, é impossível encontrar em inglês uma sílaba que termine em [h]. A impossibilidade se deve ao fato que os sons [ŋ] e [h], em inglês, ocorrem em ambientes exclusivos: [ŋ] em final de sílaba e [h] em início de sílaba.
Nestes casos, avalia-se o grau de diferença fonética entre os sons para defini-los ou não como fonemas. Se os dois sons tiverem várias diferenças fonéticas então eles serão definidos como fonemas distintos. Este é o caso em inglês para [ŋ] e [h]. Temos que [ŋ] é nasal e [h] é oral; [ŋ] é vozeado e [h] é não-vozeado, [ŋ] é velar e [h] é glotal.
A identificação de fonemas deve idealmente considerar todos os contextos ou ambientes em que cada som ocorre na língua. Isto porque o contraste fonêmico pode, em alguns casos específicos, ser restrito a ambientes ou contextos específicos, como veremos no caso dos arquifonemas.
Temos também casos em que não se encontra pares mínimos para caracterizar dois SFS como fonemas distintos porque cada um dos sons ocorre em contexto específico, como veremos no caso de alofones.
O contexto ou ambiente define o local na palavra em que um determinado som ocorre. Alguns contextos fonológicos relevantes são:
| V ____ V | contexto intervocálico (entre vogais) |
| # ____ | início de palavra |
| ____ # | final de palavra |
| ____ + ____ | limite de morfema |
| ____ $ ____ | limite de sílaba |
É a partir do exame do contexto ou ambiente em que os sons ocorrem que podemos caracterizar os alofones e os arquifonemas que ocorrem em um sistema fonológico.
A análise fonológica de uma língua deve explicar a ocorrência de cada som nos contextos ou ambientes em que ocorrem naquela língua, bem como limitar a ocorrência dos sons em contextos que eles não podem ocorrer.
Alofones são sons que não estão em contraste fonêmico. Alofones são pronunciáveis e representados entre [colchetes]. Todo alofone é obrigatoriamente relacionado a um fonema.
Os sons que correspondem aos alofones podem ser substituídos um pelo outro sem prejuízo de significado das palavras. Por exemplo, no final de sílaba em português os sons [l] e [w] podem ocorrer sem prejuízo de significado porque as pronúncias [sal] ou [saw] ‘sal’ apresentam o mesmo significado.
Neste caso, a alofonia dos sons [l] e [w] é restrita ao final de sílaba. Observe que em início de palavra como em [ˈlah] ‘lar’, ou em posição intervocálica como em [aˈlo] ‘alô’ e também em encontros consonantais, como em [plaˈkah] ‘placar’ os sons [l] e [w] não podem ser substituídos um pelo outro sem prejuízo de significado das palavras.
Quando se tem dois sons relacionados com um mesmo fonema, como no caso de [l] e [w], devemos definir qual dos sons representará o fonema. A escolha é pautada no som que tiver a distribuição mais abrangente na língua. No caso de [l] além de ocorrer em final de sílaba como em [sal], é um som que ocorre em início de palavra como em [ˈlah] ‘lar’, em posição intervocálica como em [aˈlo] ‘alô’ e em encontros consonantais como em [plaˈkah] ‘placar’. Uma vez que [l] tem distribuição mais ampla do que [w] no português, o símbolo escolhido para representar o fonema é: /l/. O fonema /l/ tem relação com os alofones [l] e [w] no português.
Em outras línguas [l] e [w] podem ser definidos como fonemas. Por exemplo, em inglês temos que /l/ e /w/ são fonemas que podem ser caracterizados pelo par mínimo: [laɪ] ‘lie’ e [waɪ] ‘why’.
Vimos que [l] e [w] são alofones em português e fonemas em inglês. Portanto, fonemas e alofones são elementos específicos de cada língua.
Alofones são identificados após SFS não terem sido definidos como fonemas.
Exemplos:
Nestes casos, deve-se investigar se os SFS são alofones. Alofones podem ser livres ou contextuais.
6a. Alofones livres
Podem ocorrer no mesmo contexto, mas as palavras não tem o significado diferente (se as palavras tivessem o significado diferente os SFS então seriam fonemas).
Considere [h] e [x]. No português brasileiro palavras, como [ˈmah] e [ˈmax] ‘mar’ ou [ˈhã] e [ˈxã] ‘rã’ não apresentam significados diferentes quando o som [h] ou [x] ocorre.
Dizemos que os alofones [h] e [x] estão em variação livre no português brasileiro. Casos de variação livre foram estudados na Sociolinguística a partir da década de 70 como tendo correlatos sociais: idade, sexo, classe social, etc.
Como definir qual é o fonema que engloba os dois SFS que são alofones livres? Escolhe-se um dos SFS, seja [h] ou [x] e assume que ele representa o fonema: /h/ ou /x/.
Alternativamente, pode-se sugerir uma outra representação para o fonema, neste caso, por exemplo, pode ser /R̄/ (Cristófaro Silva 2010).
6b. Alofones contextuais
Alofones contextuais ou alofones posicionais ocorrem em contextos exclusivos. Onde um som ocorre o outro não ocorre. Alofones contextuais ou alofones posicionais dependem do contexto ou da posição que os sons se encontram.
Alofones contextuais definem a distribuição complementar ou variação contextual (é o contexto que determina quando um som ou outro ocorre).
Considere [d] e [dʒ]. No português brasileiro, [dʒ] ocorre sempre seguido de [i] e [d] ocorre ‘Nos Demais Ambientes’ (NDA).
| [dʒ] | [d] | |
| seguido de [i] | adia, ditado, mordi | – |
| NDA | – | dado, dedo, duro, drama |
A tabela mostra que sempre que [dʒ] ocorre logo em seguida ocorre um som [i]. Por outro lado, [d] ocorre seguido de vários outros sons, exceto [i].
Em casos de Distribuição Complementar, onde um som ocorre o outro não ocorre (contextos exclusivos):
Como definir qual é o fonema que engloba os dois SFS que são alofones contextuais na distribuição complementar?
Escolhe-se como fonema o alofone que tem distribuição mais abrangente. No caso de [dʒ] e [d] tem-se que [dʒ] é restrito ao contexto seguinte ser [i]. Por outro lado, [d] é abrangente: ocorre nos demais ambientes (NDA). Por ter ocorrência abrangente, /d/ é definido como fonema:
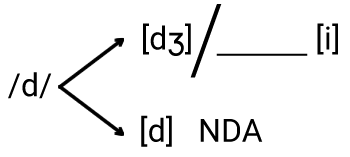
Lê-se: O fonema /d/ se manifesta como [dʒ] quando seguido de [i], e se manifesta como [d] nos demais ambientes (NDA).
Em uma distribuição complementar temos um /fonema/ que se relaciona aos vários [alofones].
Fonemas estão no nível fonêmico e são representados entre barras transversais. Alofones estão no nível fonético e são representados entre colchetes.
O formato de regra fonológica que segue foi utilizado no transição entre o modelo Fonêmico ou outros modelos estruturalista e o Modelo Gerativo.
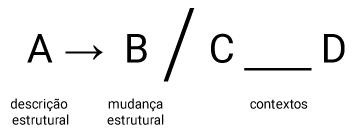
Toda regra prevê que um fonema (entre barras transversais) – que neste caso é /A/ – vai se transformar (a seta indica a transformação) em outro som – neste caso /B/, quando estiver em um determinado contexto que é indicado por ______ , e que neste caso é precedido de C e seguido de D.
Na regra acima, entende-se que: o fonema /A/ da descrição estrutural sofrerá a transformação e terá a mudança estrutural portanto se manifestando como o fone [B], no contexto que é precedido de [C] e seguido de [D].
No caso da alofonia contextual de [dʒ] e [d] discutida acima teremos a seguinte regra:
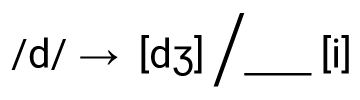
Na regra acima, entende-se que: o fonema /d/ da descrição estrutural sofrerá a transformação e terá a mudança estrutural portanto se manifestando como o fone [dʒ], no contexto que é seguido de [i].
Em alguns casos SFS são identificados como fonemas da língua, mas o contraste entre eles é perdido em certos contextos. A neutralização caracteriza que dois (ou mais fonemas) que estejam em contraste, perdem este contraste em contexto específico.
Considere as sibilantes [s, z, ʃ, ʒ]. Estes quatro SFS estão em contraste fonêmico que pode ser comprovado em palavras como ‘assa, asa, acha, haja’ ou ‘seca, Zeca, checa, jeca’. Portanto, são fonemas: /s, z, ʃ, ʒ/.
Contudo, no contexto posição final de sílaba o contraste fonêmico entre /s, z, ʃ, ʒ/ é perdido. Isso porque /s, z, ʃ, ʒ/ podem ocorrer no final de sílabas como [s, z, ʃ, ʒ] em exemplos como: mês, vesga, festa, mesmo.
Para representar a perda do contraste fonêmico em contexto ou ambiente específico fazemos uso de arquifonemas.
O arquifonema é um elemento que expressa a perda do contraste fonêmico decorrente da neutralização e é geralmente representado por letra maiúscula que se encontra entre /barras transversais/. No exemplo ilustrado em que /s,z,ʃ,ʒ/ perdem o contraste fonêmico em posição final de sílaba a análise convencional do português sugere que represente-se o arquifonema por /S/.
As transcrições fonêmicas apresentam estritamente fonemas e arquifonemas que são elementos representados entre /barras transversais/. Portanto, alofones contextuais e livres não estão presentes nas transcrições fonêmicas.
No caso da alofonia de [dʒ] e [d] temos que as pronúncias [ˈdʒiə] e [ˈdiə] ‘dia’ têm a mesma transcrição fonêmica: /ˈdia/.
No caso da neutralização dos fonemas /s, z, ʃ, ʒ/ têm-se que as pronúncias [ˈmes], [ˈmez], [ˈmeʃ] terão a mesma transcrição fonêmica com o arquifonema /S/: /ˈmeS/.
O Quadro Fonêmico do Português que é apresentado abaixo foi proposto por Cristófaro Silva (2010). Temos 19 fonemas consonantais e 7 fonemas vocálicos no português, além de 3 arquifonemas.
Todo quadro fonêmico deve listar os fonemas vocálicos e consonantais da língua, bem como os arquifonemas se ocorrerem na língua. É desejável que alofones sejam listados no quadro fonêmico para indicar a pronúncia possível dos fonemas.
Clique aqui para obter a versão para impressão do Quadro Fonêmico do Português apresentado a seguir.


Um exame da lista de alofones do quadro fonêmico do português mostra, por exemplo, que o alofone [i] tem relação com o fonema /i/ e também com o fonema /e/. Um exemplo do alofone [i] relacionado com o fonema /i/ seria a primeira vogal da palavra ‘pirata’. Por outro lado, um exemplo do alofone [i] associado ao fonema /e/ seria a primeira vogal da palavra ‘perigo’ que pode ocorrer como [i] em diversas variedades do português brasileiro. A questão que se coloca é: ao se deparar com as palavras ‘pirata’ e ‘perigo’ o pesquisador utilizará qual critério para definir o fonema vocálico da primeira sílaba destas palavras?
Infelizmente, em casos que o mesmo alofone se relaciona com dois fonemas diferentes, no mesmo contexto, não é possível definir com qual fonema os alofones se relacionam. Neste caso temos a sobreposição fonêmica que caracteriza uma situação em que dois fonemas distintos têm a realização fonética.
Em línguas bastante estudadas, como por exemplo o português, a etimologia ou o conhecimento da diversidade linguística pode oferecer esclarecimentos sobre o sistema fonológico. Mas em línguas menos estudadas, a caracterização fonêmica pode ser polêmica.
Desafios teóricos como este imposto pela sobreposição fonêmica oferecem elementos para a formulação de novas perspectivas teóricas.